Appendices: Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover
Appendices
What would change my mind about the path of least resistance?
If our approach to AI development is “train more and more powerful RL agents on diverse tasks with a variety of human feedback and automated rewards,” then I expect an AI takeover eventually, even if we test for unintended behaviors and modify our training to eliminate them. I don’t think an AI takeover is inevitable -- but if we avoid it, I think it’ll be because we collectively got worried enough about scaling up baseline HFDT that we eventually switched to some other strategy specifically designed to reduce the risk of AI takeover (see this appendix for a flavor of what kind of measures we could take).
What could change my mind about the baseline HFDT and iterative ML safety? What would make me feel like we’re likely to be fine without any special efforts motivated by a fear of AI takeover? The main answer is “someone pointing out ways in which these conceptual arguments are flawed.”1 I hope that publishing this post will inspire people who are optimistic about baseline HFDT and iterative/empirical ML safety to explain why this outcome seems unlikely to them.
However, optimists often take a very empiricist frame, so they are likely to be interested in what kind of ML experiments or observations about ML models might change my mind, as opposed to what kinds of arguments might change my mind. I agree it would be extremely valuable to understand what we could concretely observe that would constitute major evidence against this view. But unfortunately, it’s difficult to describe simple and realistic near-term empirical experiments that would change my beliefs very much, because models today don’t have the creativity and situational awareness to play the training game.
As an illustration that’s deliberately over-extreme, imagine if some technologically less-advanced aliens have learned that a human spaceship is about to land on their planet in ten years, and are wondering whether they should be scared that the humans will conquer and subjugate them. It would be fairly difficult for them to design experiments on mice2 that would give them a lot of information about whether or not to be scared of this. They would probably be better off speculating from their priors than trying to extrapolate from observations on mice.3
I think we have significantly more hope of designing experiments on small models that give us meaningful updates about AI takeover risk,4 but I take this analogy more seriously than most ML researchers seem to. Accordingly, I’m fairly unmoved by empirical experiments that ML researchers have cited to me as evidence about the magnitude of x-risk from AI.
With all that said, here’s a stab at a general genre of empirical evidence that would probably move my views a lot if it were demonstrated in large quantities across different domains:
- Convincingly demonstrate that a pre-trained model has a certain “capability,” for example “recognizing the color red.” E.g. you might show that it consistently and correctly predicts the color of stop signs, strawberries, etc.
- Describe an RL fine-tuning procedure that seems like it would select for / incentivize the use of that capability, e.g. “reward the model every time it approaches a red object.”
- Then make a prediction that the model would in fact not use that capability and instead do some other particular thing, e.g. “the model would actually approach purple objects because gradient descent is biased to find ‘seeking purple objects’ more natural.”
- Demonstrate that this prediction was correct.
I expect most people to think that it would be very hard to generate such results, including those who are much more optimistic about AI takeover than I am. I think this is another case of optimists and pessimists interpreting evidence differently -- to me, expecting a powerful model not to play the training game is essentially making a claim that we understand a particular way in which gradient descent is consistently suboptimal, so I would want to see researchers succeed at the task of “guess the particular way in which gradient descent will be suboptimal” a lot of times to feel better.
“Security holes” may also select against straightforward honesty
In the main body, I implicitly acted as if the reward Alex gets in the lab setting is always under the control of some specific designated humans,5 and discussed ways in which Alex might try to play on those humans’ biases or ignorance.
But in reality, Alex’s reward is ultimately generated and recorded through a series of specific operations carried out on some Magma servers. This means there are likely some operational and computer security vulnerabilities Alex could exploit to bypass “official channels” for reward entirely:6
- If Alex is able to get access to whichever computer records logs of its actions and sends them to human evaluators, it may be able to arbitrarily edit the record of its actions to make itself look more reasonable, helpful, or intelligent before they are reviewed by human evaluators. (For example, it may go back and edit any incorrect predictions it made with the benefit of knowing what happened in hindsight.)
- If it’s able to access the website or software that human evaluators use to enter their scores, it could spoof the scores in various ways. As a simplified example, it may produce outputs that look like routine instructions to the contractors, which tell them to enter a “thumbs up” as part of an attention check. As another example, it could edit the back-end logic so that pressing a “thumbs down” button would result in actually recording a “thumbs up” in the relevant database(s).
- It could bribe a Magma employee into modifying its reward signals, e.g. by offering to feed them good ideas that would get them promoted or helping them embezzle money from the company.
I am unsure whether and how often Alex would take actions like this in the lab setting, and consider this more speculative than softer ways of playing to human biases:
- Humans would consider these kinds of actions to be more blatant and scary violations of expectations than softer ways of playing to human biases, which they may not recognize as bad even if it’s staring them in the face. That means if this is discovered later Alex is likely to retroactively receive a large negative reward and/or trigger a larger retraining project. Alex would likely understand this, so it’s a question of its motivation structure whether it would still take these opportunities. It may do so if it inherently cares about maximizing short-term reward, or it may avoid them if it cares about something longer-term.
- Depending on Magma’s security practices, these opportunities may be quite rare, and/or it may consistently be easier (in terms of compute or time constraints) for Alex to try to maximize reward in more “normal” ways (which would still involve a large amount of manipulation).
Nonetheless, this consideration contributes to my expectation that Alex would end up playing the training game. If it does try something like this, even as an exploratory action, that action would be self-reinforcing. Whatever moved Alex to try this kind of act, doing it would immediately lead to a gradient update in the direction of those inclinations -- barring the fact that humans would penalize it if discovered. But even if it is later penalized, that may not be enough to reverse the inclinations; see this appendix.
Simple “baseline” behavioral safety interventions
In this appendix, I’ll discuss several simple proposals for training Alex to have safer behavior, and explain why I think they would simply change the game Alex is playing rather than altering its motive to play the training game:
- Maybe we could train Alex on very high-quality feedback, and/or try to teach it to extrapolate from lower-quality feedback to higher-quality feedback? (more).
- Maybe we could use prompt engineering to directly ask Alex to emulate much wiser and more thoughtful evaluation? (more).
- Maybe we could require Alex to provide evidence, arguments, or justification that humans can understand for its actions? (more).
- Maybe if we make the training distribution very diverse, different types of errors in the reward signal would “cancel out” and prevent misgeneralization? (more).
- Maybe we could include a number of situations in the training distribution in which Alex is rewarded for being “conservative” -- avoiding unusual actions, checking in when it’s in a strange new situation, etc (more).
Using higher-quality feedback and extrapolating feedback quality
To avoid Alex learning to manipulate or deceive its evaluators, we could have more careful / thoughtful / informed humans evaluate how Alex interacts with less-informed / less careful / less thoughtful humans. Perhaps some training episodes involve Alex answering questions for humans who believe the Earth is flat, but its “honesty” reward signal ultimately comes from a group of humans who know the Earth is round. Then Alex would be incentivized to be honest to the flat-earthers rather than telling them what they want to hear.
There could also be a sequence of such steps. As a caricature, imagine that first Alex interacts with 3rd graders while being evaluated for honesty by 6th graders, and then with 6th graders while being evaluated for honesty by 9th graders, and then with 9th graders while being evaluated by 12th graders, and so on. We might hope that after many instances of “learning the lesson” that it will be evaluated by a human better-informed than the one it’s interacting with, Alex would learn to “play it safe” by always being honest.7
This intervention would likely stop Alex from attempting certain kinds of deceptive or manipulative moves (creating the appearance of success). However, it wouldn't make complete honesty the reward-maximizing strategy. At its level of situational awareness, Alex would easily understand that the humans designing this training scheme can’t actually continue to supply arbitrarily better-informed evaluators. In reality, there will be some “most informed and thoughtful human evaluators the designers could plausibly employ to evaluate this episode,” and Alex could simply act as if those humans are evaluating it at all times.
There are still ways in which the most informed and thoughtful humans available could be manipulated or deceived to increase reward. If the Catholic Church were training Alex in the 1400s, ensuring that its reward signal is only generated by the brightest scholars of the age as anointed by the Church would still not make maximal honesty the best strategy. Alex would still be learning to manipulate some set of humans (in this case, the “final level” of supervisors) to get high reward, leading to the dangerous generalization discussed in the main piece.
Using prompt engineering to emulate more thoughtful judgments
Large language models such as GPT-3 will change the way they respond to questions or requests based on what came previously in the prompt. For example, prompting GPT-3 with something like “You are a wise and knowledgeable AI advisor trying to help a human figure out what’s true” will tend to cause its responses to questions to be more accurate; asking questions with poor spelling and grammar will tend to cause its responses to get less accurate.
(Setting up prompts to elicit certain behaviors like this is called prompt engineering.)
Some researchers have suggested that we might be able to leverage prompt engineering to help with ML alignment for very large models which are presumably very sensitive to prompt changes.8 For example, we could prompt Alex with something like “Act how a very wise and very ethical human that’s as knowledgeable as you are would act if they had a long time to think about it,” or we could ask it to explain how a very wise and ethical human would evaluate its past actions. We could also search (through trial-and-error or gradient descent or some combination) for prompts that empirically seem to induce the best behavior.
However, if Alex has a good understanding of its human evaluators and knows that they are attempting this kind of prompt engineering, Alex would simply respond to such prompts by doing its best to act the way ordinary humans think that an unrealistically wise / ethical / knowledgeable person would act. This may make its behavior superficially better in some cases -- but Alex could still sometimes achieve higher reward by being deceptive or manipulative (e.g., providing answers that seem good rather than answers that are good), leading to the dynamics described above.
Requiring Alex to provide justification for its actions
Another suggestion for improving alignment is to require Alex to prove or argue or demonstrate that its actions are aligned. For example, Alex might provide an easily-checkable proof that a mathematical theorem it claimed to discover is true, or it might provide an empirical demonstration of a physical phenomenon it claimed to discover.
This would likely work well in areas like math and physics where arguments and demonstrations are unusually cheap and decisive. However, in many important domains -- e.g. policy, economics, sociology, parts of biology, etc -- crisp and decisive “proofs” are intractable, and human evaluators will be forced to try to make sense of softer kinds of arguments and evidence which leave a huge amount of room for interpretation. Even “rigorous scientific studies” can easily be confusing and misleading and consistent with any number of conclusions based on the reader' priors (and for many claims it would be too expensive to generate such evidence in the first place).
Furthermore, there are likely some areas where human evaluators (including the best accessible human evaluators) are predictably wrong about the kind of arguments that best demonstrate truth, not just wrong about object-level claims. Consider the version of Alex trained by the medieval Catholic Church again -- the Church’s worldview would be oriented around Biblical hermeneutics and/or papal declarations being the ultimate arbiter of truth when different sources of evidence conflict.
More broadly, I’m not aware of anyone sincerely believing that “having the arguments and papers people find most persuasive” is tightly and reliably coupled with “being the most correct.” It probably buys some amount of correctness on average, but most of us can name many qualitative arguments we think are deeply flawed that lots of other smart people nonetheless consider decisive (e.g. because the arguments prey on some of those people’s biases).
So as in the above sections, this approach would still lead to cases in which Alex could get better reward by being less truly honest/helpful/harmless (though more apparently honest/helpful/harmless), and hence to the problematic dynamics described above.
We could try to salvage the idea of “require Alex to demonstrate that what it’s saying is true” with something like debate or amplification, both of which essentially try to recursively break big difficult-to-evaluate claims into sub-claims (which are broken down into further sub-claims etc) such that the smallest sub-claims are simple enough and uncontroversial enough that we can be highly confident all human evaluators would get them right and agree about the answer (e.g. claims like “Does ice float in water?” or “Are giraffes generally bigger than dogs?”).
However, it’s very unclear if it’s possible to recursively break down important big-picture questions like “Is this action helpful, honest, and harmless?” into these very easy and objective subquestions -- as far as I know, nobody has demonstrated a working solution here. The only systematic empirical investigation of debate that I know of (using humans in the place of models) ultimately concluded that dishonest debaters often have a strategy that lets them win debates.
Moreover, even if we can find a working debate or amplification strategy, there’s no guarantee that it will be as efficient (in terms of computation or data) as baseline HFDT -- it could simply turn out to be much easier to acquire knowledge than to explain or justify it to humans (see this section of Alignment Research Center’s 2021 report “Eliciting Latent Knowledge” for more discussion). If that’s the case, it could create a lot of pressure to “cut corners” and do something more like baseline HFDT rather than debate or amplification.
Making the training distribution more diverse
Some researchers argue that making the training distribution more diverse -- adding many different kinds of situations which call for very different approaches or heuristics -- would reduce the probability that Alex violates what humans intend. The idea is that if the training distribution is relatively narrow, there are many possible ways to generalize under distribution shift, and the more we include novel situations that benefit from using very different tactics the more we’re eliminating “wrong” ways it could generalize.
For example, this paper showed that if we try to train an agent to collect a gem in a maze, but the gem always happens to be yellow in the training set, then the agent will seek yellow objects rather than gems when both are present. If we had trained the same agent on a more diverse distribution with gems in a huge variety of colors, then it’s more likely it would “correctly” (according to its designers’ intent) pursue gems in the test distribution -- “shape” is more likely to be the most salient thing in common between all the objects it’s rewarded for collecting, since we’ve eliminated “color” as a possibility by varying color.
Similarly, maybe if Alex only ever receives human feedback from one type of human with a particular knowledge base and set of biases (e.g. “software engineers working at Magma”), it’s likely to “overfit” to that kind of human and learn to exploit their weaknesses and gaps in their knowledge. But maybe if it were exposed to feedback from a really broad array of different humans with different values, strengths and weaknesses, areas of knowledge and misconceptions, etc, different people’s errors and biases would “cancel each other out” such that Alex would learn to “factor out” these flaws and just be honest?
We could also imagine manufacturing more “artificial” kinds of diversity -- e.g. situations where humans try hard to model the opposite of standard human biases like the sunk cost fallacy or risk aversion, or simulated environments where being highly docile and cooperative turns out to be the best strategy for getting reward, or situations where e.g. Alex interacts with a Democrat but its responses are evaluated by a Republican. The idea is to create so many different kinds of scenarios with different strange things happening that hopefully the only common thread between them all is the generalization Magma engineers were going for.
Introducing a lot of diversity in how reward is generated would likely increase Alex’s uncertainty about what is going on in any given episode, compared to a more straightforward training curriculum in which Alex is always given normal tasks and evaluated on normal metrics of performance. In that sense, there could be some effect of different biases and errors “canceling each other out” -- if Magma researchers successfully cause Alex to be uncertain whether it’s in a tricky scenario or an ordinary scenario, or whether it’s interacting with a political conservative or liberal, it may indeed often act less manipulatively or dishonestly in the face of that uncertainty.
However, increasing diversity doesn’t seem like it would cause Alex to “forget” the basic situation it’s in -- that it’s a machine learning model being trained by some humans to be useful, intelligent, helpful, honest, harmless, etc. And by the same token, it doesn’t seem like it would cause Alex to stop trying to maximize reward -- it would simply change the strategy that best maximizes reward. And as with the previous examples, the new best strategy would probably not be to be straightforwardly helpful, honest, and harmless at all times:
- Alex could pick up cues about what “general kind of person” is likely to evaluate the current episode, and develop guesses about their level of knowledge, political ideology, personal biases, and so on.
- Alex could also pick up soft cues about whether its current episode is likely to be a “strange tricky episode” or one that’s being “played straight.”
- Alex can be pretty confident that some kinds of manipulative tactics (e.g. flattery) are fairly universal.
- Many egregious reward-grabbing actions may remain open to Alex, if they would require more careful investigation to catch than humans are likely to bother with.
The underlying dynamic would be the same overall: Alex would be being trained to do something like “behave in ways that appear honest, helpful, and harmless, but behave in other ways when it is possible to evade detection and doing so leads to higher reward.” For a capable enough Alex, this could still present plenty of opportunities for the latter.
Additionally, increasing diversity could also make the situation worse, by strongly developing Alex’s creative planning faculties and forcing it to use them a lot. In a narrower distribution, it might not incur much penalty to follow a simple set of heuristics based on what worked well in the past (like today’s models often use), and we could conceivably carefully engineer a narrow training distribution such that the heuristic “be helpful, honest, and harmless” is always reward-maximizing (though this would be difficult).
On the other hand, Alex is less likely to be able to memorize simple heuristics that cover all the cases in a very diverse distribution that contains many “tricky” episodes. Asking itself “How can I figure out how to maximize reward in this episode?” probably works better than following heuristics like “do something basically reasonable,” by an amount that scales with how often it’s encountering situations that aren’t like anything it’s seen before.
Adversarial training to incentivize Alex to act conservatively
Magma engineers could try to train Alex to be “harmless” by putting it in various situations where it would seemingly increase reward to take some kind of egregiously harmful or norm-violating action (a kind of adversarial training).
For example, researchers could put Alex in a situation where it apparently has the opportunity to execute a code injection attack on the website that the human evaluators interact with, allowing it to edit all reward scores to the max score. They could then give it a large negative reward for taking the opportunity, and a positive reward for refraining and/or checking in with a human. They could also search (manually, with gradient descent, with the help of other models, etc) for situations in which Alex is especially likely to do the wrong thing, and include many such situations in its training distribution.
As with increasing diversity above, adversarial training is likely to create some amount of additional uncertainty about whether apparent opportunities to increase reward by violating norms are actually “sting operations” by human supervisors. This will probably make Alex less likely to attempt certain bad actions (e.g. fraud, theft, hacking) to get reward (even in some cases where it could have gotten away with it, since it will be imperfect at predicting which opportunities are setups and which are real).
But it’s unclear whether it’s possible to generate a distribution of adversarial training episodes which ensure that the reward-maximizing strategy never does anything norm-violating or harmful.
In the course of its training, Alex is likely to learn things about the world that it can be pretty confident no human understands (just as AlphaGo knows things about Go that no humans know, or AlphaFold knows things about biology that no humans know). If it then discovers e.g. a zero-day exploit which it can only recognize because of knowledge it’s developed about computer hardware that it’s fairly confident Magma engineers don’t know, it can safely exploit that vulnerability (e.g. to directly edit the reward entered in its training dataset) because it’s unlikely to be entrapment by humans.
As Alex does more and more scientific research and gains more and more knowledge, it becomes more and more likely that it can find opportunities for egregious reward-grabbing that humans wouldn’t have been able to fake in a training setup. Getting rid of all such opportunities seems to involve either a) ensuring that humans can “follow along” with Alex and understand everything new that Alex learns at about the same time as Alex, or b) letting humans “read Alex’s mind” to discern its intentions. Research directions that might help us do this -- such as mechanistic transparency, eliciting latent knowledge (ELK), or relaxed adversarial training -- are early-stage, and it’s unclear how far they’ll get.
“Training out” bad behavior
Perhaps if Magma researchers notice that Alex did something bad to maximize reward (e.g. lied to its evaluator or exploited a security vulnerability as described in this appendix), they can reverse Alex’s motivation to do that sort of thing with further intervention? For example, maybe they can get it to stop playing the training game altogether, or at least only engage in “soft manipulation” rather than more acutely scary actions?
Researchers might try editing the rewards associated with those episodes to show large negative values, they might conduct audits to uncover other instances of egregious reward-grabbing and retroactively give those large negative rewards, they may try adversarial training in which Alex is given the apparent opportunity to grab reward, and so on.
However, as with other safety interventions, these reactive safety interventions don’t seem like they would reverse Alex’s motive to grab reward. Rather than learning to never take bad actions, Alex seems more likely to learn not to take such actions when it’s plausible that humans could go back and give negative reward to them later.
That is, it would continue to try to maximize expected reward in any way it can, while shifting the notion of “reward” that it’s maximizing to be the final reward that ends up recorded in association with that training episode, after all rewrites and revisions are over.9 As before, changing the training game predictably leads Alex to get more expected (long-run) reward than adopting the policy of never taking egregious reward-grabbing actions.
“Non-baseline” interventions that might help more
Here are several ideas for how we could go beyond taking the appearance of good behavior at face value:
- We could try to come up with an alternative training process that we have strong reason to believe wouldn’t run into the problem that HFDT runs into, even on arbitrarily powerful models.
- We could be careful to only train models that are not capable of taking control from humans, and try to use advice from those untrusted-but-controlled models to somehow eliminate further danger -- e.g., get them to solve AI alignment more fully in a way that works for much more powerful models, or get them to figure out how to institute strong international bans on deploying more powerful models, etc.
- We could do adversarial training specifically to reduce the probability that a model would take control from humans if given the chance -- that is, try to generate inputs that fool the model into thinking an AI takeover is possible, and select against models that would take that opportunity. Likely we would need model assistance for this -- we could reward one model for finding inputs that fool another model.
- We could try to understand models’ internals well enough to figure out ways to directly select for models that “have the right motives” (as opposed to the right behavior), or to “read models’ minds” to figure out whether we should deploy them.
- We could provide training to human evaluators to make them less susceptible to manipulative and dishonest tactics, and instruct them to give reward primarily or entirely based on whether the model followed honest procedures rather than whether it got good results. We could try to use models themselves to help explain what kinds of tactics are more and less likely to be manipulative.
- We could improve computer security in AI labs, to make it harder for moderately powerful AI systems to gain unauthorized access to their rewards or gradients. We could also train AI systems to propose additional improvements that we can verify (while being careful to ensure that the systems looking for flaws in our security setup are not themselves able to easily break out).
- We could train several different kinds of models and set them all up against each other in a system of checks and balances during deployment. For example, some models could be in charge of predicting future indicators of a possible AI takeover, such as “what the security cameras in various data centers will show” or “what newspapers will be reporting.” Other models could be rewarded for demonstrating takeover plans hatched by other AIs.
A forthcoming post by my colleague Holden Karnofsky goes into much more detail about safety measures that could prevent AI takeover.
Examining arguments that gradient descent favors being nice over playing the training game
In this appendix, I’ll briefly summarize arguments that gradient descent may favor honest and straightforward strategies like “doing what designers intended” over “playing the training game” even if the latter gets more reward, and explain why I don’t find them persuasive:
- Maybe telling the truth is in some general way “easier” or more “natural” than deception? (more).
- Maybe Alex internalizes attitudes like “lying is bad” early in training while it’s still weak, and this sticks around? (more).
- Maybe we have evidence that gradient descent tends to generalize surprisingly “well,” compared to what might be expected from theoretical arguments? (more).
Maybe telling the truth is more “natural” than lying?
Some people have the intuition that it would be in some broad sense “simpler” or “easier” for gradient descent to find a model that plainly states what it internally believes than one that maintains one set of beliefs internally while presenting a different set of beliefs to the world. By analogy, humans find it mentally taxing to weave elaborate lies, and often end up deceiving themselves in the course of deceiving others.
If the “always be honest” policy received almost as much reward as the policy that plays the training game, it seems possible (though far from certain)10 that an effect like this could end up dominating. But in fact, I expect the honest policy to get significantly less reward than the training-game-playing policy, because humans have large blind spots and biases affecting how they deliver rewards. I’m skeptical that something like “honesty being somewhat simpler or more natural” would make the difference in that case. Most humans are not regularly in situations where lying has a very high expected payoff -- and in such situations humans often do lie even though it’s difficult (consider undercover agents whose lives depend on not getting caught).
Maybe path dependence means Alex internalizes moral lessons early?
A related argument suggests that early in training (while Alex perhaps has low situational awareness and/or planning ability), taking actions that look like “figuring out clever ‘hacks’ to get more reward ‘illegitimately’” would be caught and given negative reward; this might instill in it the heuristic that taking actions which pattern-match to “clever hacks” are generally undesirable. Maybe once it “grows up” it realizes that it could get away with deceptive tactics, but perhaps by then such tricks internally feel “unaesthetic” or “immoral.”
By analogy, kids are taught not to steal from people in contexts where it’s easy for adults to catch them if they try, since they’ll be incompetent at it. Most children grow up to be adults who’ve internalized a general aversion to theft, and who avoid it even when they know they could get away with it in a particular instance. Most adults aren’t constantly on the lookout for cases where they could get away with breaking the rules.
I find this unpersuasive for two reasons:
- I don’t think it makes sense to bank on Alex developing a particular kind of internal moral commitment or sentiment, especially one held with enough force to overcome the fact that shedding it would result in substantially more reward. Instead of developing an affinity for being straightforward or an aesthetic aversion to clever hacks, it could develop any number of other affinities and aversions that happened to correlate with doing well early in training (e.g. “be curious,” “avoid sameness,” etc). And even if something like “an aversion to clever hacks” were initially part of its psychological landscape, I’m skeptical that this kind of dynamic would survive and dominate in the face of consistent and significant rewards for deception.
- Even before Alex is ever trained with RL, it already has a huge amount of knowledge and understanding of the world from its predictive and imitative pretraining step. It may well already have strong situational awareness and a good grip on the concept of “reward” in RL, e.g. from reading so many papers about RL. I don’t think it makes sense to analogize it to an impressionable “child” at the start of HFDT -- it may latch onto the policy of maximizing reward nearly immediately given its existing knowledge.
Maybe gradient descent simply generalizes “surprisingly well”?
A number of ML researchers who are bullish on deep-learning-based transformative AI seem to have the background heuristic that gradient descent empirically tends to generalize “better” than might be expected by theoretical arguments. For example:
- We might have thought that gradient descent would only work well for convex tasks, because it would get stuck in not-very-interesting local minima on non-convex tasks. But in fact it works well in practice for a large number of realistics tasks that are clearly not fully convex.
- We might have thought that models trained on a certain distribution would generalize very poorly to a different distribution, but in fact models trained on a reasonably broad initial distribution (like language models trained on the internet) generalize reasonably well zero-shot to various different tasks -- and this generalization improves with model scale.
- We might have thought that models with “too many” parameters relative to training data points would overfit to the training dataset and generalize poorly on future examples, but the deep double descent phenomenon shows that “overly large” models first generalize somewhat worse, and then generalize better as their size increases.
Examples like these lead some researchers to adopt a heuristic that gradient descent works surprisingly well compared to what we might expect based purely on theoretical arguments, and (relatedly) theoretical arguments that gradient descent is likely to find a particular kind of model are usually wrong and given our lack of empirical data we should have wide priors about how future models will behave. Such researchers often tend to be optimistic that with empirical experimentation we can find a way of training that produces powerful models that are “docile,” “nice,” “obedient,” etc., and skeptical of arguments (like the one I’m making in this post) that gradient descent is more likely on priors to find one kind of model than another kind of model.
But what exactly does it mean for gradient descent to work surprisingly well? An intuitive interpretation might be that it’s surprisingly likely to produce the kinds of models we’d hope it would produce -- this is what people usually are pointing at when they say something is going “well.” But I think a more realistic interpretation is that gradient descent is surprisingly likely to produce models that get a very high reward (on the training distribution), and/or generalize to doing the sort of things that “would have” gotten a high reward (on a different distribution).11 My concern is about situations in which doing the sorts of things that maximize reward comes apart from what we should be hoping for.
A possible architecture for Alex
Thanks to Jon Uesato for suggesting a variant of this architecture, and to Buck Shlegeris for helping me work out details I was confused by.
Because it processes a long series of observations within a single episode, Alex needs to have some sort of architecture that allows for sequence processing. One example might be a transformer architecture that attends over the last K observations at once.
While transformers are more common for state-of-the-art language models as of 2022, I’ll imagine here that Alex is some type of recurrent neural network (RNN) because that’s simpler to visualize. For example, you could imagine Alex is an LSTM network, though there are many other recurrent architectures we could imagine. In reality, the sequence processing would likely be significantly more complicated and may combine elements of various RNN architectures with transformer-like attention and other mechanisms -- you can feel free to substitute whatever architecture you think is most appropriate for processing sequences.
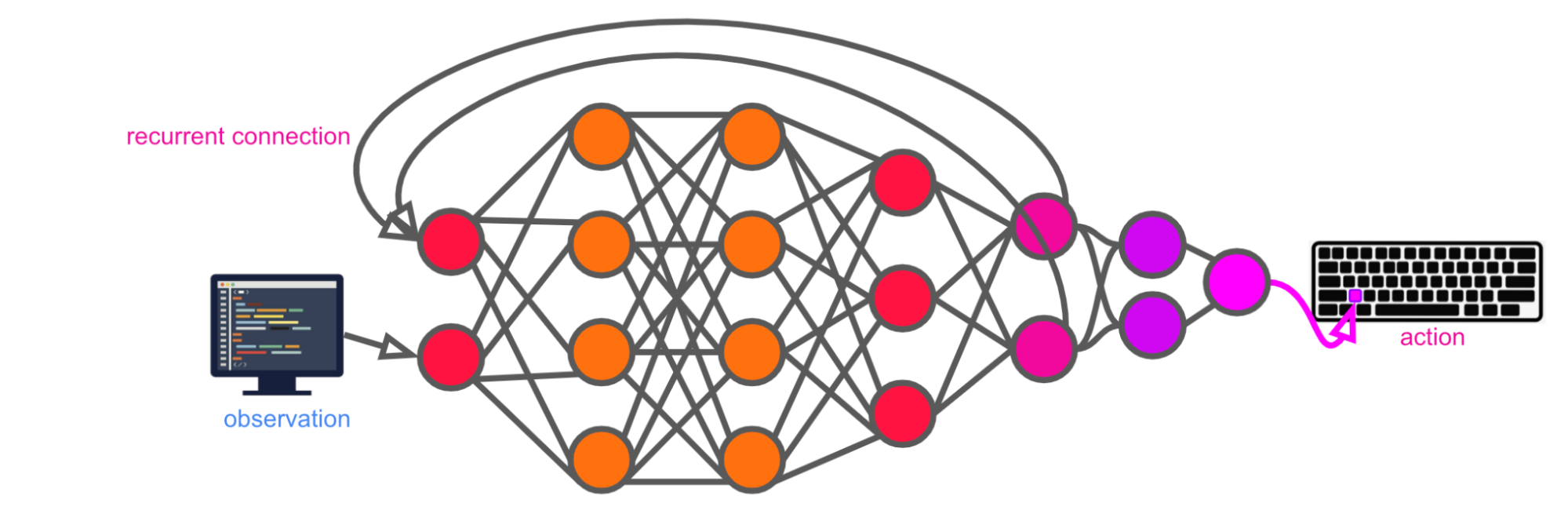
The diagram above show that at every timestep, Alex takes a single observation12 -- plus its own hidden state from the previous timestep -- as input, and produces a single action as output.
Let’s say it also outputs a prediction of the next observation13 and the final episode reward (both conditional on taking the action) as auxiliary tasks every timestep. The observation prediction task is meant to help it build up an understanding of the dynamics of interacting with the computer, while the reward prediction task is meant to help it more quickly connect decisions to their impact on overall task performance.
While RNNs carry forward a “train of thought” or “short-term memory” across multiple timesteps, they generally have a limited ability to “remember” things over very long time periods. This is an issue because Alex will have to do tasks that could take many millions of timesteps to complete (e.g. a single episode may cover the process of investigating an odd phenomenon, generating hypotheses, conducting experiments to test the hypotheses, settling on an explanation, and writing a paper of the findings).
Magma researchers and engineers might get around this limitation in a number of possible ways. They may use a different architecture entirely for sequence processing,14 or they may somehow break down otherwise-long episodes into shorter chunks,15 or the accumulation of tweaks to optimization algorithms or RNN architectures in the time between now and then might have effectively eliminated this issue.
To keep this story concrete, I’ll sketch out a broad kind of architectural modification that might help with this issue, if a number of technical details were hammered out. The basic idea is that Alex is equipped with a database that it can interact with to store and retrieve its “long-term memories.” We’ll imagine for concreteness that a “memory” is some subset of Alex’s activations and/or weights at a certain point in time, but it could have any other format.
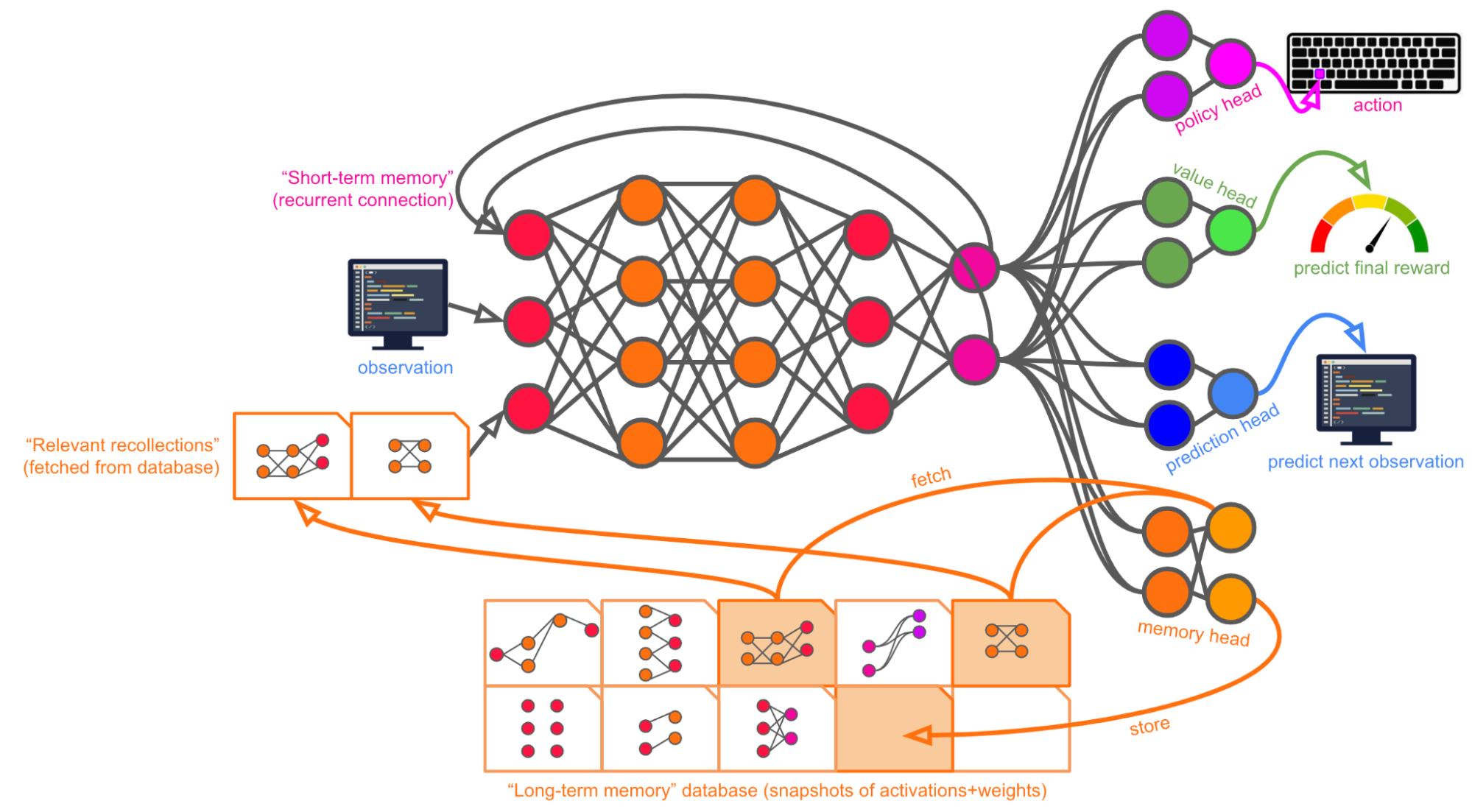
At the beginning of an episode, Alex’s memory bank is wiped clean -- this is sort of analogous to a new “clone” of Alex being “born,” with certain “genetic predispositions” (in the form of its weights) but no “individual life experience” yet.
Within each timestep of an episode, Alex is able to a) store any activations and/or weights from the current timestep that it wants to, and b) send a query to retrieve any previously stored activations and/or weights that might be relevant, handing those to itself as inputs for the next timestep. Over the course of an episode, the memory bank builds up a store of “lifetime experiences” (though some experiences can also be “forgotten” if desired).
In addition to this dedicated memory bank, it’s important to note that Alex can use the computer it’s interacting with as an external memory aid in exactly the same way humans do -- it can write notes to itself in Google docs, create Asana tasks, set Google calendar reminders, and so on. If taking actions like that helps it to get a higher final reward for the episode, the training process will select for that.
This means that (like humans) Alex will have both “direct” experiential memories and access to external memory aids.
Plausible high-level features of a good architecture
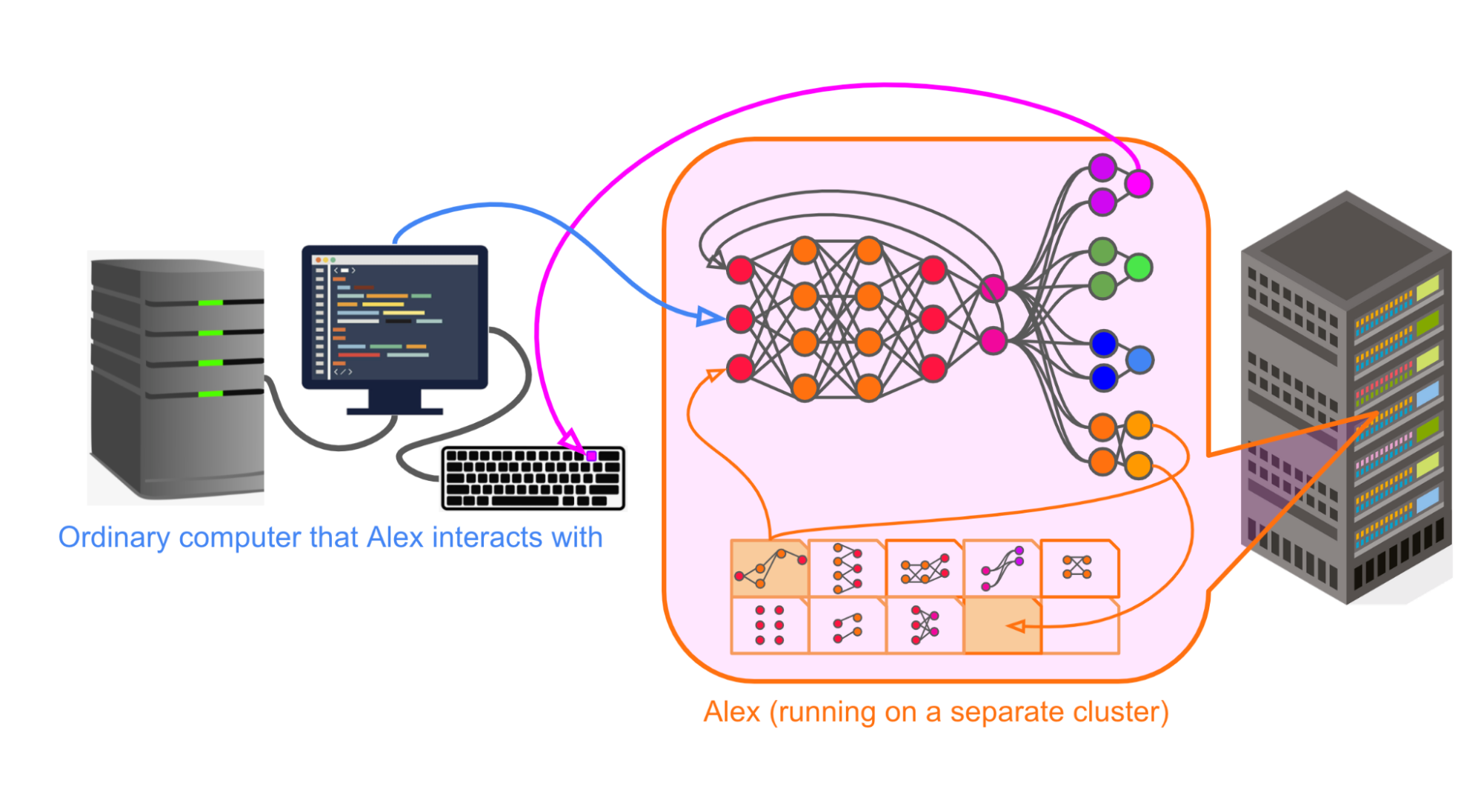
Stepping back, the high-level picture of Alex interacting with the external computer, with the details of the architecture sketched out, looks like this:
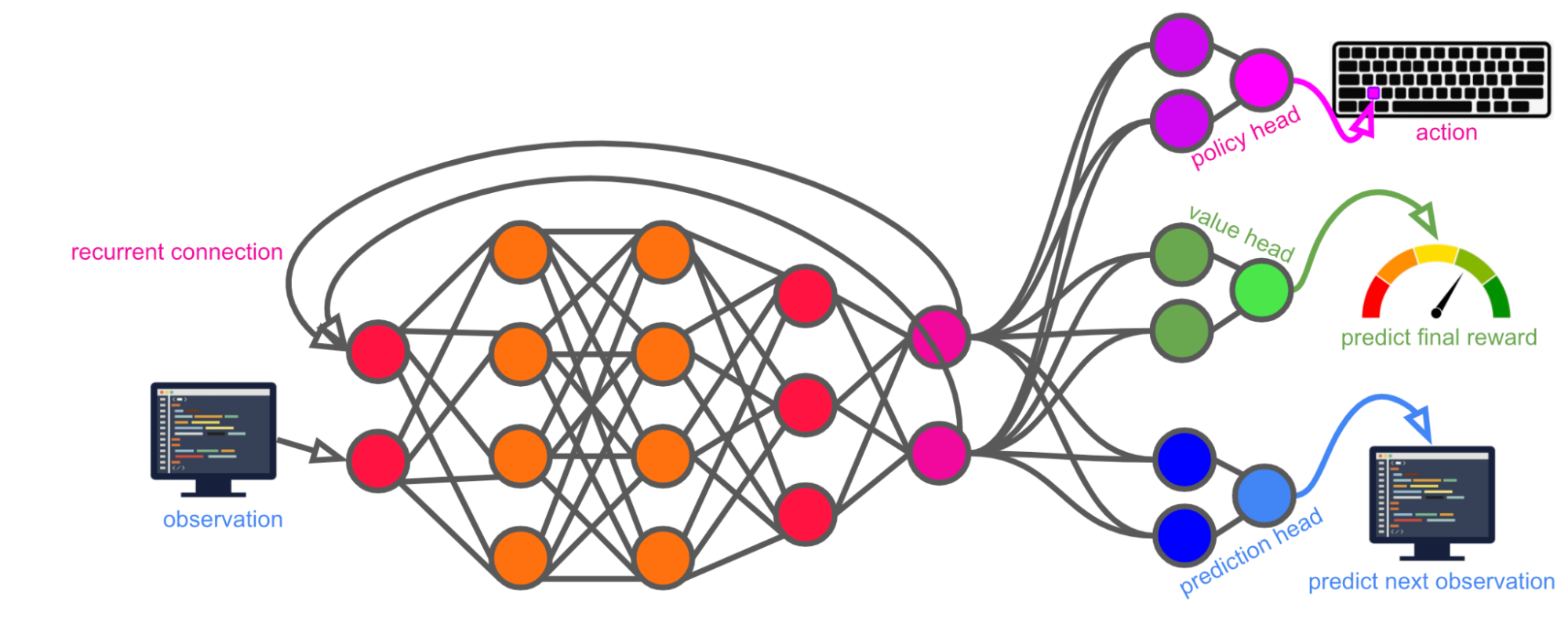
In every timestep, Alex:
- Takes as input:
- An observation from the external computer (such as an image of the screen)
- Its previous hidden state (via a recurrent connection)
- Some number of memories retrieved from the long-term memory database
- Produces as output:
- An action (such as a keystroke). The action space includes a no-op and encompasses every low-level action a human could take on a computer.
- A store query and a fetch query to its long-term memory database, representing “memorizing” and “recalling” (respectively) a certain life experience.
- A prediction of the final reward for the episode, conditional on taking the action from a) and sending the store+fetch queries from b).
- A prediction of its next observation, conditional on taking the action from a) and sending the store+fetch queries from b).
I tried here to err on the side of being overly specific because I think it can be helpful to have in mind a vivid picture of a particular architecture that could conceivably suffice for a transformative model, even though it’s highly unlikely to literally be accurate.
With that said, I think that whatever future architecture we might use to train a transformative model with HFDT is pretty likely to have a few key high-level features in common with my over-simplified sketch:
- Some form of sequence processing (whether attention, recurrence, something else, or some combination of architectures)
- A way to reliably store and recall “memories” / “life experiences” over long timescales (this might be automatically solved by whatever solution is found for the above)
- Input and output formats which allow for a lot of flexibility, so that the model can process many different kinds of inputs and perform many different kinds of low-level actions (though this may be accomplished with a large number of different specialized input and output channels rather than a generic “universal” input channel and output channel as I’ve depicted here; we might also use entirely new data formats optimized for machine consumption)
None of the basic points made in the main post hinge on the specifics of Alex’s architecture. However, my arguments do rely on the high-level properties above -- e.g. that Alex has a very general and flexible input/output space and can usefully remember things across many timesteps. I think these properties are important for the case that Alex can potentially have a transformative impact in the first place, and by the same token are important for the case that Alex might be extremely dangerous.
Footnotes
-
For example, stronger arguments that benign generalizations are especially “natural” for gradient descent, enough to make up for the fact that playing the training game would get higher reward; stronger arguments that Alex would “generalize habits” rather than “generalize goals” from training to deployment. ↩
-
Say the mice were dropped off on an earlier spaceship. ↩
-
Thanks to Buck Shlegeris for suggesting this analogy. ↩
-
For one thing, our mouse-brain-sized models have a different and more human profile of abilities than actual mice (e.g. they can talk). ↩
-
(who either deliver reward directly or write code that delivers reward) ↩
-
Humans would consider egregious reward-grabbing acts to be more blatant and scary violations of expectations than softer ways of playing to human biases, so if Alex is later caught it is likely to receive a large negative reward and/or trigger a larger retraining project. I discuss below why I think that isn’t likely to be sufficient to change its motives to grab reward. ↩
-
See Turning reflection up to 11 for a similar proposal. ↩
-
For example, Eric Jang, citing Connor Leahy on Twitter, writes: “Just asking the AI to be nice sounds flippant, but after seeing DALL-E and other large-scale multi-modal models that seem to generalize better as they get bigger, I think we should take these simple, borderline-naive ideas more seriously.” ↩
-
Note that Alex is likely to be motivated to maximize the “final recorded reward” even if it’s ultimately interested in pursuing some other goal. For example, if Alex is trying to have some kind of lasting effect on the world that extends beyond the current episode (e.g. “discover all the secrets of the universe”), it is probably much more likely to accomplish that goal if the future contains more models like it -- which in turn is more likely to happen if it gets a very high reward. ↩
-
Humans find lying difficult and unnatural due to our specific evolutionary history. Alex’s design and training wouldn’t necessarily replicate those kinds of evolutionary pressures. Still, it seems plausible that it would, especially since we’d be trying to give it feedback to encourage honesty. ↩
-
On a philosophical level, it’s not exactly clear what it means to talk about what actions taken in deployment “would have” gotten a high reward. But on a practical level, Alex is likely to continue to receive rewards on the deployment distribution, particularly if it’s not acting the way researchers want it to act, so the meaning of “reward on the deployment distribution” is fairly well-pinned-down. ↩
-
The high-level picture doesn’t change if we imagine it taking in an attention window of a number of observations instead. ↩
-
This prediction probably won’t be in the form of separately predicting each pixel of the next screen -- it’s more likely to be something more complicated and abstract, e.g. an English-language description of the next screen. ↩
-
Although other known sequence processing architectures, like transformers, are also currently limited in how long they can “remember” things (albeit sometimes for different structural reasons). ↩
-
This may also reduce the risk that power-seeking misalignment emerges. ↩