Supplement to “Why AI alignment could be hard”
This page is authored by Ajeya Cotra.
This post is a supplement to Why AI alignment could be hard with modern deep learning. In this post, I:
- Give a more in-depth explanation of how deep learning works with more technical detail, though I still aim for it to be fairly accessible to a general audience (more).
- Illustrate how we might train powerful deep learning models to do open-ended real-world tasks like the ones involved in PASTA (more).
How deep learning works
This section gives a high-level not-too-technical introduction to how deep learning works. It’s coming largely from a theory perspective1 since I’ve found that some of the vocabulary from learning theory is helpful for explaining concepts in alignment, so it might feel non-standard if you’re more used to explanations targeted at practitioners.
I cover:
- The basics of machine learning (ML), which you can think of as “searching over computer programs” rather than “writing down a computer program” (more).
- What distinguishes “deep learning” from other types of ML, and why it’s useful (more).
Basics of machine learning: search over programs
In ordinary computer programming, if you want to get a computer to do some task (e.g. play Tic-Tac-Toe well), you need to give it a set of precise and explicit instructions for exactly what to do (e.g. “If you’re player 1, start in the top left corner. If you’re player 2 and player 1 hasn’t taken the middle, go in the middle, otherwise…”). These instructions are called an algorithm; to write an algorithm for a task, you need to understand in detail how to do the task yourself.
But what if you’re not very good at Tic-Tac-Toe yourself, and want to write a program that plays better than you can? In that case, you could potentially list out every possible Tic-Tac-Toe strategy -- every possible opening move, every possible counter-move to each opening move, every possible counter-counter-move to each counter-move, and so on -- and then play all these strategies against each other to find which one wins most often. With this approach, you don’t need to know the algorithm for winning Tic-Tac-Toe. You just need to know the basic "template" for an algorithm (e.g. it should take as input all the moves made by both players so far, and produce as output a legal next move) -- then you can try out a lot of different ways of “filling in the blanks” in that template to get specific algorithms.
I would consider this second approach (of trying all the possible Tic-Tac-Toe strategies) to be a very basic type of machine learning (ML),2 which is essentially a bunch of different techniques you can use to search3 for an algorithm that solves some task through trial-and-error rather than writing down the solution yourself. You need four basic ingredients in an ML setup:
- A search space: This is a way of defining the whole “universe” of possible algorithms that you’re going to search through to find one that solves the task. In the Tic-Tac-Toe example, the search space is all possible functions that take as input a history of moves made so far (e.g. “X played in the top right corner, then O played in the middle, then X played in the far right of the second row”) and produce as output a legal next move (e.g. “O plays in the bottom middle”).4 Once you know that any solution must take this form, it’s straightforward -- though time-consuming -- to generate a bunch of particular examples of candidate Tic-Tac-Toe-playing algorithms. Whether or not you are a strong player yourself, you know one of those possible algorithms must be a strong player. The search space is often also called the model class, and the individual elements in the search space are called candidate models.
- A training dataset and a performance metric: Once you have specified a model class such that at least one of the candidate models performs well on the task you’re interested in, you need a strategy for picking out which one that is. To do that, you need to test candidate models on a large set of examples of the task you want to solve (the training dataset), and have a way of numerically scoring how well a candidate model did on an example (the performance metric). In an image classification task like the popular ImageNet, the training dataset is a set of images along with human-provided labels saying what the image is a picture of (e.g. “bicycle” or “Beagle”); a performance metric could be “1 if the model picked the right label for the image, and 0 if the model picked the wrong label.” In the Tic-Tac-Toe example and other games like chess or StarCraft, there’s no pre-existing dataset and the training data is generated implicitly by playing a lot of games; the performance metric in this case is “1 if the model won the game, -1 if the model lost the game, 0 if the model drew the game.”
- An optimization algorithm: This is an algorithm which specifies how exactly to search through the space of candidate models to find one that performs well, given a search space, training dataset, and performance metric. In the Tic-Tac-Toe example, the optimization algorithm I proposed was approximately the simplest possible one: just try every single candidate model against every other candidate model. This optimization algorithm is called “exhaustive search” or “brute-force search”. Real-world machine learning methods use more sophisticated optimization algorithms that avoid having to try every candidate model in the model class, which is usually astronomically more efficient. Many techniques use some form of local search (this refers to a family of different optimization algorithms). A local search algorithm first picks one candidate model at random, then tries a bunch of possible small tweaks to that model5 until it finds one which performs better than the original model, and then repeats this process until it finds a pretty good model. For example, you might start with a random Tic-Tac-Toe strategy, have it play games against a copy of itself, then try changing a handful of its moves at random until you find a new strategy that beats the first strategy, then iterate that process until you find a strategy that seems strong overall.
Deep learning: gradient descent on deep neural networks
There are lots of different techniques that fit the basic mold outlined above (i.e. “use some kind of optimization algorithm to search over some space of candidate models to find a model that does well according to some performance metric on some training dataset”). Each specific ML technique makes a choice about what kind of model class to use and what kind of optimization algorithm to use, and that in turn will impose some restrictions on what kind of datasets and/or performance metrics it can work with. For example, linear regression is a very simple and limited ML technique where:
- The data points must be pairs of numbers6 (x, y) e.g. (temperature, ice cream sales) or (lead in soil, crime rates).
- The model class is the space of all possible linear functions from x to y: all functions of the form y = a*x + b. a and b are called parameters; each specific way of filling in values for these parameters (e.g. a = 24.578 and b = 3.87) generates a unique candidate model that can make a prediction for what y will be given a value of x.7
- The performance metric must be squared error: the square of the actual y minus what the candidate model predicts (based on its values for a and b).
Because of these restrictions, the optimization algorithm for linear regression -- the process used to find the right values of a and b which get the best performance -- can be very specialized and efficient. (In fact it doesn’t have to do any “search” at all in the conventional sense; it can directly compute the best values for the parameters.)
Deep learning is a particular subset of ML which uses a large neural network to define the model class and gradient descent as the optimization algorithm which searches for the best model in the class. There are a number of other techniques in the broader ML umbrella, but empirically, the strategy of “do gradient descent on neural networks” seems to be most powerful and cost-effective at large scales for many useful tasks. Researchers have used this basic strategy to get near-human or superhuman performance on a wide variety of pretty general-purpose tasks such as vision, natural language, speech recognition, motor control, real-time games, protein-folding, etc when other types of ML or software development didn’t work very well. In large part this is because deep learning is unusually flexible and generic -- unlike linear regression, it imposes very few restrictions on the dataset or performance metric, and doesn’t require the programmer to know very much about how the final solution will look.
In the sections below, I explain how neural networks define the search space (and why they’re useful), and how gradient descent finds a good model from the space.
Deep neural networks
In the linear regression example above, y = a*x + b was a “template” for the candidate models, and the parameters a and b were essentially “blank spaces” we could “fill in” to pick out a particular candidate model like y = 24.578*x + 3.87 or y = 7.09*x - 0.438. We can represent this template with a diagram like this (called a computational graph):
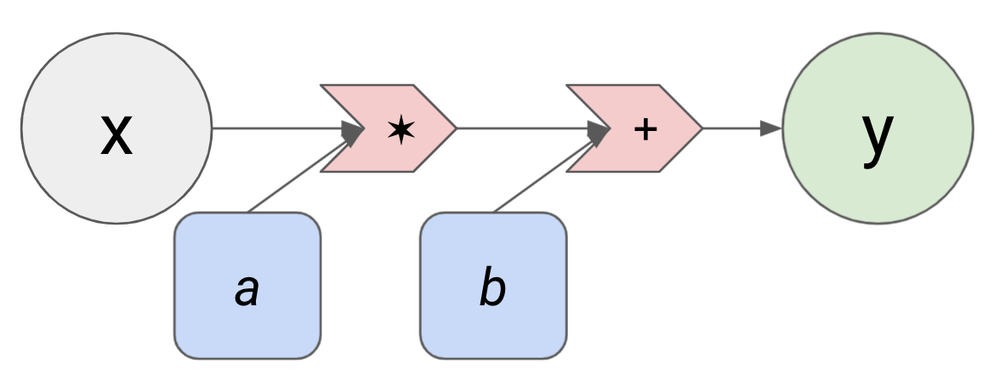
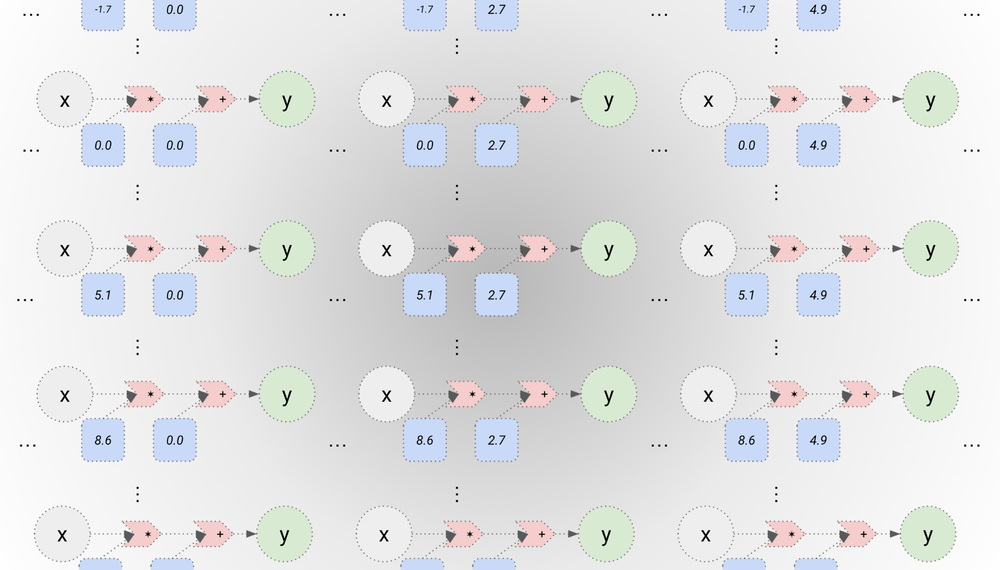
The grey circle is the input, the blue rounded rectangles are the parameters, and the green circle is the output. The red arrows are simple arithmetic operations -- addition and multiplication. This computational graph shows that the input x and the first parameter a are multiplied together, then the result is added with the second parameter b to produce the output y. Every different pair of numbers we choose for a and b (every parameter setting) produces a different function that converts from x to y. This defines a model class for linear regression, which we can visualize as a cloud of computational graphs with different parameter settings:
Neural networks are essentially the same as this: they can also be represented as a computational graph where inputs are combined with parameters to produce outputs, and they define a model class because each different setting of the parameters corresponds to a different candidate model. But the computational graph of a neural net is somewhat more complex than the computational graph of a linear model, and there are many more parameters.
Example of a simple neural network
Here’s a computational graph for a very small version of a very simple type of neural net (a feedforward network):
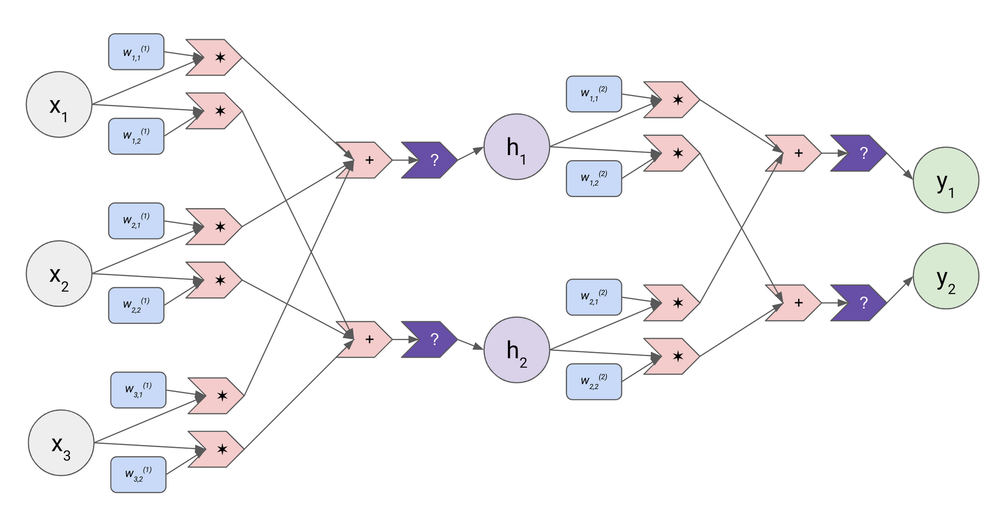
Once again the grey circles are inputs and the green circles are outputs. Rather than working with single numbers, neural networks work with vectors (essentially lists of numbers). This neural network takes a vector of length three (x1 , x2 , x3) as an input and produces a vector of length two (y1 , y2) as its output.
A neural network’s computation is arranged into layers; the example network shown above has two layers. It has ten parameters overall (again represented as blue rounded rectangles), which are also called weights8 because they are used in a weighted sum. Six of these weights are part of the first layer; they’re all marked with the superscript (1) to indicate they belong to the first layer. These six weights are used to combine together the individual components of the input vector (i.e. x1 and x2 and x3) into two completely separate weighted sums:
- The first weighted sum uses all the weights marked with a “1” in the far right: w(1)1,1 * x1 + w(1)2,1 * x2 + w(1)3,1 * x3. In the diagram these weights sit above the input component they are multiplied with.
- The first weighted sum uses the other set of weights, marked with a “2” in that slot: w(1)1,2 * x1 + w(1)2,2 * x2 + w(1)3,2 * x3. In the diagram these weights sit below the corresponding input component.
Each weighted sum is then passed through a nonlinear function (the dark purple arrow), which means that unlike the rest of the computational graph this function isn’t just doing addition and/or multiplication. There are a few options for this piece, but one that’s extremely simple and works well simply “zeros out” the input if it’s negative and keeps it unchanged if it’s positive. After the weighted sum is passed through the nonlinear function, it’s called a hidden neuron or activation; in the computational graph, the hidden neurons are the light purple circles h1 and h2.
And then the whole weighted-sums-then-nonlinear-function process is just repeated. You can think of the vector (h1 , h2) as a whole new “input vector” with its own set of weights. We again make two weighted sums with the four weights on the second layer: w(2)1,1 * h1 + w(2)2,1 * h2 and w(2)1,2 * h1 + w(2)2,2 * h2, and again pass those weighted sums through a nonlinear function, which finally results in the output (y1 , y2).
This is the basic formula of a neural network:9 in each layer the inputs to that layer are combined into weighted sums in a bunch of separate ways, then those weighted sums are passed through a nonlinear function and become the inputs for the next layer. Because the operations are always the same, we can simplify the computational graph by omitting them:
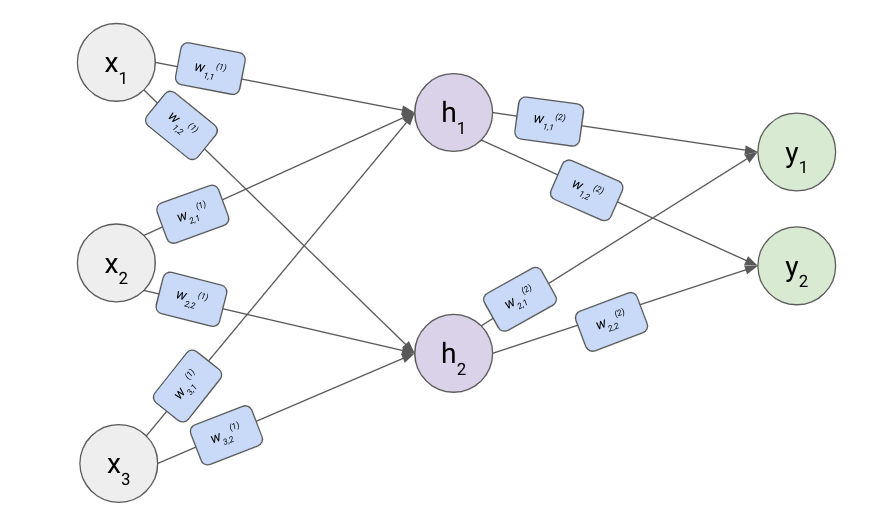
As in the linear regression example, each setting of the weights corresponds to a different candidate model in the model space (I’ll illustrate below with just two weights changing but we’d actually be changing all ten weights at once):
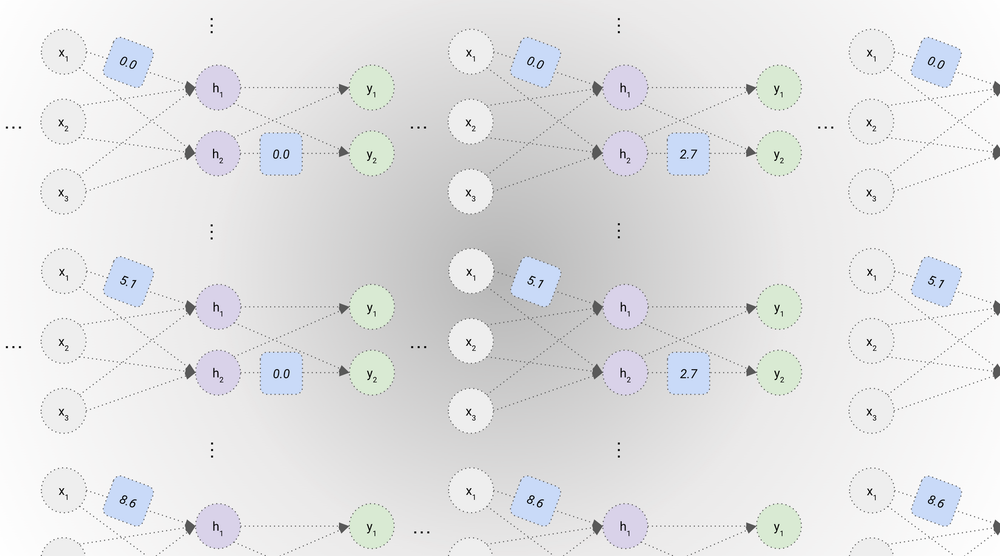
Notice we could have had any number of hidden neurons in the middle layer (e.g. we could have used nine weights rather than six in the first layer and had three hidden neurons, or twelve weights and had four hidden neurons, etc). Similarly, we could have had any number of layers between the inputs and the outputs rather than just one.
A “deep neural net” is just an informal term for neural nets which have many layers (e.g. dozens or hundreds), each of which has many neurons (e.g. thousands or tens of thousands). The largest deep neural nets regularly used today have hundreds of millions of hidden neurons in total, connected together by hundreds of billions of weights.
Why use deep neural networks to define the model class?
Why is this particular way of defining a model class so popular? Essentially, I think it’s because it offers extraordinary flexibility. First of all, basically any kind of input type and output type you’re interested in can be pretty easily turned into a giant list of numbers:
- An image can be turned into an ordered list of pixels, with the color of each pixel represented by a number (e.g. an RGB color code). A video can just be a series of images represented in this form, which we can feed into the neural net one by one.
- Board games are similar to images: each square can be treated as a “pixel,” and instead of a number representing what color it is, there can be a number representing what pieces have been played. E.g. in Tic-Tac-Toe, you could represent an X as a 1, an O as a -1, and a blank square as a 0. In chess you could designate a number for each of the twelve unique pieces (the black and white versions of king, queen, rook, bishop, knight, pawn). The model can output its next move by “drawing a picture” of what the board should look like next using this same format.
- Video games could be represented literally as a sequence of images showing the exact pixels that a monitor would display for the human, or as a more abstract list of numbers where each type of object in the scene (enemy, ally, treasure chest, etc) has a numerical code, and there’s a numerical code indicating the location of the object.
- When there’s a finite set of options for the output, we can turn that into a vector. For example, in ImageNet there are a thousand different possible labels for images; this can be represented as a list of 1000 numbers where each position in the list represents one of the possible labels. If the correct label for an image is “Corgi,” then we would put a 1 in the position corresponding to “Corgi” and 0s everywhere else. The model could represent its guess with a similar type of vector, but rather than having 1 on the right answer and a 0 everywhere else it could put probabilities on each option.
- Even language can be converted into the “finite set of options” format -- a simple way to do this is to have a vector of length 77 which has a position for each of the 26 letters both lower-case and capitalized, each of the 10 digits, each of the 14 punctuation marks, and the space. Then you can feed the model text one letter at a time, and the model could also “speak” one letter at a time. You can expand this by giving common words (e.g. “the”) or parts of words (e.g. “-ing” or “un-”) their own spot in the vector too.10
Secondly, neural networks are very flexible in the kinds of functions they can represent. There’s a theorem which says that a sufficiently large neural network can represent virtually11 any kind of function mapping one vector to another as long as you can specify the right weights. (I like this chapter of Michael Nielsen’s deep learning textbook for a fairly intuitive walkthrough of the proof.) And more importantly, it seems to be borne out in practice that we can actually design deep neural networks that do a whole bunch of useful and interesting things when we can find a way to represent the inputs and outputs we care about as vectors -- the functions they end up representing are extremely complicated and subtle, and would have been difficult or impossible to write down ourselves.
Stochastic gradient descent
Once we’ve set up our neural network and our input vector and output vector, how do we find the right setting of weights -- one that represents a useful function, such as good image classification, good Go-playing, good language prediction, etc? We can use a form of local search called stochastic gradient descent (SGD).
As I said above, local search is a kind of optimization technique where you start with a randomly-selected candidate model (in this case a random setting of weights), see how that model performs on some data points, try to find a slight change (a “perturbation”) that improves performance, and repeat that process until performance is strong. The simplest type of local search would involve just generating some number of perturbations at random at each step, testing all of them, and picking the best one. For example, with our example neural network above, that could look like this (again just focusing on two parameters):
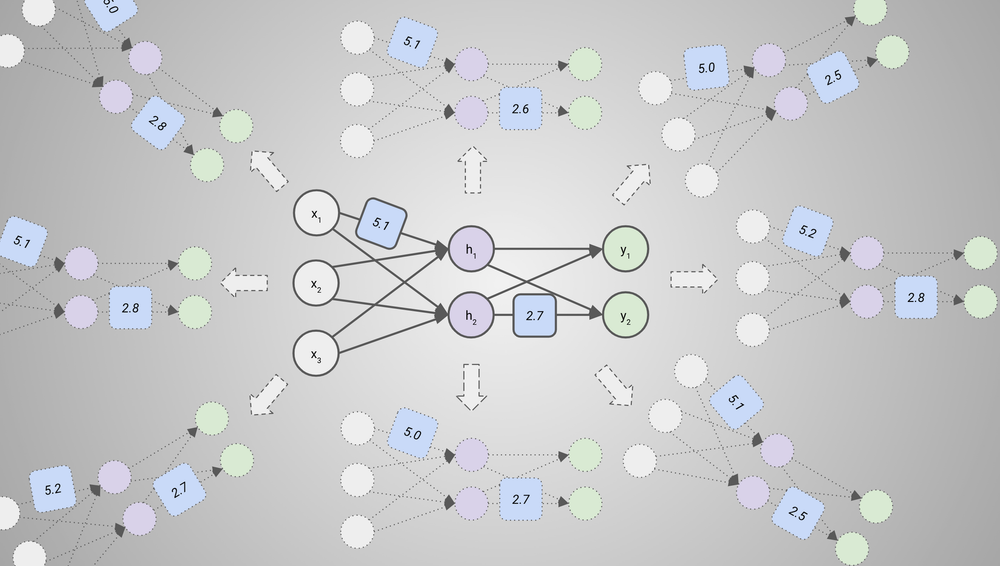
This method can work okay, but when you’re trying to perturb billions of parameters, it gets too expensive to get a good enough sample size of possible perturbations. SGD improves on this by intelligently calculating the most helpful perturbation rather than just generating some options at random and trying them all. Essentially, for each parameter you can calculate the (partial) derivative of performance with respect to that parameter: how performance on the data points you’re using for this round would change if you were to increase the value of that parameter a little bit, while holding the other parameters fixed. If you have this information for all the parameters at once, that’s called a gradient.12 Once you have this information, you can perturb the weights in a way that improves performance by bumping each one up or down based on which direction would improve performance according to the gradient. Conceptually, it’s like if you got to try every possible direction at once rather than having to sample some directions.
How we might produce superhuman models with deep learning
So far, we have produced AI systems that are superhuman at narrow and “clean” tasks that don’t involve interaction with the real world, such as playing Go or figuring out how a protein would fold, and we have some progress (though not human-level performance) in fuzzier domains such as natural language. How could we train models that are superhuman at open-ended real-world tasks like the ones involved in PASTA?
As described above, we would need a) a search space of candidate models, b) a training dataset and performance metric on that dataset, and c) an optimization algorithm to find a candidate model from the space that has high performance on the training dataset. Let’s assume that we are using deep learning, aka: the search space is defined by some sort of deep neural network, and the optimization algorithm which finds the right setting of weights for the neural net is derived from13 SGD.
In the rest of this section, I’ll briefly sketch out:
- How large and computationally powerful a neural network may need to be to achieve superhuman performance in open-ended domains (more).
- Some simple examples of dataset(s) and performance metric(s) that may be used for producing a superhuman model (more).
How big would these models need to be?
Larger neural nets -- ones that have more weights and use more computation to process each data point -- are generally capable of representing intuitively more “intelligent” and “sophisticated” behaviors, given the right setting of weights (discovered via SGD).14 However, they also generally need to process a lot more training data points to realize this greater potential.15 I expect that a neural network which could improve on human performance at the most complicated and open-ended tasks that smart humans do would need to be much larger than ones we’ve trained so far (and therefore would need to process much more data during training). But how much larger would it need to be?
Many people would say the answer is “astronomically larger” or “large enough to not be worth thinking about.” While the universal function approximation theorem says that there is some neural network and some setting of weights that corresponds to every way of converting inputs like sights and sounds into outputs like words and motor movements, that doesn’t mean it has to be practical to find the one that spits out words and motor movements corresponding to “insightful policy analysis” or “effective hardware R&D.” Maybe we’d need a neural net running on a computer the size of Saturn and more training data points than there are atoms in the Milky Way, for example. Alternatively, maybe there is a smaller neural network out there which is theoretically capable of the task, but it’s astronomically unlikely that SGD will be able to find the right setting of weights for that model.
In contrast, I think it’s pretty plausible that it would be affordable to train such models using SGD in the coming decades. Prima facie, I think the computational power needed to “match” the human brain is a very suggestive anchor point for how big the neural network in question may need to be, and my best understanding is that a) the human brain is not astronomically powerful, and b) there is little evidence establishing that brains are radically more computationally efficient than today’s neural nets, and a bit of evidence plausibly supporting the opposite. A model about as powerful as a human brain seems like it would be ~100-10,000 times larger than the largest neural networks trained today, and I think could be trained using an amount of data and computation that -- while probably prohibitive as of August 2021 -- would come within reach after 15-30 years of hardware and algorithmic improvements.
I won’t be discussing the reasoning behind these numbers in this post, instead taking as a premise that the required model size is likely to be large but accessible on the order of decades. See my draft report on AI timelines for a more detailed and precise treatment of this question (or Holden’s summary here). Alternatively, see this short blog post by Daniel Kokotajlo which gives a flavor for the kinds of applications that seem like they could be possible with a boost in hardware that is dramatic but (I think) achievable in the next few decades -- I don’t fully agree with it but I think it does a good job giving a flavor for the potential of deep learning systems.
Example datasets and performance metrics
What would the dataset(s) and performance metric(s) look like? We would need to gather a lot of information that helps indicate what behaviors are good/desired/competent and what behaviors are bad/undesired/incompetent in domains like engineering R&D, venture capital, policy analysis, etc. At a high level, this could take one of three forms:
- “What would a human do?” E.g., “Given an English language spec asking for a more energy-efficient computer chip, what proposed designs do human hardware engineers mock up in CAD?” This kind of data is just records of human actions given various inputs. For example, what investment decisions would human VCs make, given descriptions of potential startups (and other info about them such as growth figures or recordings of founder interviews)? What words would human policy analysts write, given descriptions of a proposed tax policy? Depending on the domain, a good amount of this kind of data already exists on the Internet and in private company databases, and more can be gathered (e.g. by filming humans or recording keystrokes on their computer). With this kind of data, the performance metric would measure how closely the model’s behavior matches the humans’ behavior, or how difficult it is to distinguish between a model and a human.
- “What would a human approve of?” E.g, “Given a CAD design for a new type of computer chip, how would human hardware engineers rate that CAD design in terms of the likelihood that it will improve energy efficiency?” This kind of data comes from the model trying out various actions (e.g. writing arguments or code) -- initially either at random or attempting to mimic humans as above -- and human judges indicating how much they approve of each action (or which of a bunch of possible actions they would approve of most). The performance metric in this case would be a quantified measure of human approval (e.g. “There’s a 74% chance that a human would approve of this proposed action,” or “The average human rater would rate this action a 4.3 out of 10”) which is backed out from a large number of such judgments.
- “What would actually work?” E.g., “Given a computer chip built from a certain design, how energy-efficient and powerful is that chip in practice once we’re using it?” This kind of data involves automatically-checkable or real-world signals of competence/goodness, which individual human judges or small groups of judges would have a difficult time predicting with high accuracy. For example, if the model writes code, we could just see if the code runs without throwing up errors and does what it was supposed to do. If the model needs to propose projects to increase sales or pick winners in the stock market, we can just check to see if sales were in fact increased or the companies it chose indeed increased in value.16 If it needs to do math, we could automatically check whether its proofs are valid.
The first kind of data, by itself, would not be enough to find a model that generates qualitatively different insights from ones that humans could generate on their own, since the resulting model would ultimately be approximating what a human would do. But it could still result in a model that functionally gets a lot more done than any human. For example, you could run such a model at a much faster “clock speed” than the human brain to get the same amount of work done in much less time, use many copies of such a model to explore a lot of possibilities in parallel, etc.
The second kind of data would likely allow models to exceed human capabilities even if they had to run at the same speed as the human brain, because it is usually easier for humans to recognize impressive behavior than to demonstrate it -- many people can appreciate the difference between a world-class athlete or writer or chef and a talented amateur, even if they themselves are much less skilled than the amateur at the task in question. (And perhaps a world-class professional could recognize superhuman performance in their field when they see it, while not being able to reproduce it themselves.)
The third kind of data has the potential to go even further than human approval -- SGD could discover models with strategies for getting good performance that humans would neither have been able to think of themselves nor immediately recognize as good using their unaided judgment.
For many applications, we would likely use a complicated and messy combination of all three types of signals (with many variants of each). For example, we might first train a model like GPT-3 that predicts what a generic, non-expert human would say, and then “fine-tune” that same model on a smaller dataset of what subject matter experts like hardware researchers or policy analysts would say, and then further fine-tune that based on a combination of expensive expert approval judgments (“Does the model’s analysis of the effects of raising the corporate tax rate make sense to me?”), cheaper non-expert judgments, and real-world signals (“Did the model’s chip design in fact reduce heating costs when we implemented it?”). The process of training may also involve more interactivity -- human overseers may actively correct models’ mistakes or give other forms of detailed feedback rather than simply rating a model’s action as good or bad, and we could train models to proactively request specific kinds of feedback at the specific points that they would be most informative.
Furthermore, for all three of these training signals, we could often replace the original signal with a model’s prediction of what the signal would say. That is, rather than literally requiring a human to press an approve/disapprove button to generate a training signal for each action taken by the model being trained, the human could only press the button 1% or 0.1% of the time and that data could be used to train a different model17 that predicts which button the human would have pressed the other 99% or 99.9% of the time.
Lastly, we would also probably combine deep learning models with “hard-coded” algorithms to some extent. For example, the AlphaGo system involves a deep learning model coming up with initial best-guess moves and then improving on those moves with a hard-coded search algorithm. In most self-driving cars, a deep learning model is used to understand the visual scene and identify which objects are which, but different algorithms are used to a) predict where the objects will move given the visual information, b) do route planning given the predictions, and c) decide exactly how to turn the wheel or how hard to push on the gas given the route. And in the future, models could -- like humans -- outsource some of their thinking to calculators and other special-purpose software.
Footnotes
-
I first learned a lot of the material I summarize in this section from the textbook Understanding Machine Learning: From Theory to Algorithms, by Shalev-Shwartz and Ben-David; I’ll be simplifying to avoid getting into the math so I encourage you to check it out if you’re interested in a solid technical introduction. Another resource I find helpful is Michael Nielsen’s Neural networks and deep learning textbook. ↩
-
But as described it’s unusual enough to be an edge case and many people might not count it as “actually” ML; that isn’t going to be relevant to the rest of the explanation. ↩
-
Even though it’s called “machine learning,” I think ML algorithms are generally more analogous to natural selection than they are to human learning, and using language that implies ML works like human learning can get confusing, especially when thinking about alignment. I’ll mostly use language like “search,” “find,” and “select” throughout this post to refer to what ML techniques do, rather than language like “learn,” “train,” and “teach” (this is one way in which my framing might differ from other introductions to ML). With that said, my view is not absolute on this; whether the kinds of ML techniques that might be used to develop TAI are actually more analogous to human learning or natural selection is largely an empirical question. ↩
-
This search space is finite, because at any given point there are at most nine possible choices for the next move, and the whole game can go for at most nine rounds. You can also have infinite search spaces, though in that case you cannot try every candidate algorithm in the space. ↩
-
In the case of gradient descent, which I describe below, the “tries” are implicit rather than explicit: gradient descent is like a shortcut to “trying” every possible small tweak at once. ↩
-
Or vectors -- I’m discussing scalars for convenience, but my descriptions apply to vectors as well. ↩
-
This search space (unlike the Tic-Tac-Toe search space) is infinite, since a and b could each be any real number. Exhaustive search (trying every possible combination of a and b) would be impossible. ↩
-
Technically there are some parameters in a neural net which are not weights, and instead modify the special functions marked in purple. But those are generally a negligible fraction of the total parameters, and it’s common to equate “parameters” and “weights.” ↩
-
A feedforward neural network is a very simple kind of neural network. There are other types of neural networks which are “wired up” somewhat differently -- e.g. they might take away some connections or add some extra connections -- but at a high level they also mostly follow this basic formula. ↩
-
For the biggest language models used today, English is represented as a 50,000-component vector which has a separate position for tens of thousands of sufficiently-common words and proper nouns like “computer” and “Stephanie” and so on. ↩
-
Subject to the function being “well-behaved” in a certain way, which I think is a pretty weak criterion. ↩
-
Neural networks became more popular once people started using a particularly computationally efficient method for calculating the gradients which cleverly reuses information from calculating the partial derivatives for the weights in the final layer to help calculate ones for previous layers more efficiently. ↩
-
ML researchers have added lots of bells and whistles to “vanilla” SGD over the years that tend to improve the efficiency of training without fundamentally changing the basic algorithm (see this blog post for an overview). This is a process which I expect to continue in the coming decades. ↩
-
What does this mean? First, given a certain desired level of performance on a given metric (e.g. 90% accuracy on ImageNet or an ELO of 2500 in chess), a larger neural net can generally reach this level after fewer training examples than a smaller neural net. Second, larger neural networks will “max out” at a higher level of performance given ~infinite training examples. ↩
-
See Hestness et al 2017 and Kaplan et al 2020 for empirical estimates of how the amount of training data required to train a model scales with model size. ↩
-
While market price signals are ultimately derived from human actions and judgments, they are still generally too complicated and chaotic for an individual human judge to predict perfectly. Most individual humans relate to the stock market in the way they relate to the weather -- treating it as an external phenomenon that they have only limited insight into. ↩
-
Or a different “head” of the same model. ↩